Правительство Индии запустило одну из самых масштабных в мире программ по оцифровке и расшифровке древних рукописей с использованием искусственного интеллекта. Миссия Gyan Bharatam, рассчитанная до 2031 года и получившая бюджет в 482,85 крор рупий (около $57 млн), уже позволила оцифровать 7,5 лакхов (750 000) манускриптов на десятках языков и письменностей. Параллельно инициатива Gyan-Setu объединяет ведущие технические институты страны для создания ИИ-прототипов, способных не просто сканировать, а понимать древние тексты.
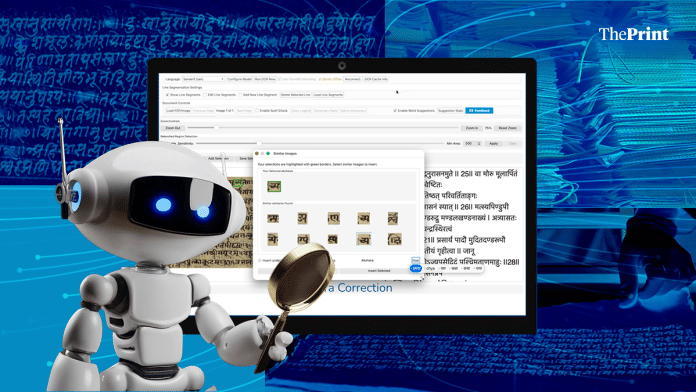
Ключевым инструментом стала платформа Lipikar, разработанная профессором Четаном Аророй из IIT Delhi. Она решает одну из главных проблем — отсутствие открытых OCR-систем для индийских письменностей. В отличие от латиницы, где распознавание символов давно стало рутиной, в индийских рукописях один и тот же символ может иметь четыре и более различных начертаний — например, в письме Кайтхи. Lipikar адаптирует оптическое распознавание символов для работы с рукописными и курсивными стилями древних и средневековых текстов.
Среди расшифровываемых документов — медные пластины Таламанчи VII века эпохи Викрамадитьи I, древние медицинские тексты из коллекции Национального института индийского медицинского наследия (NIIMH) в Хайдарабаде, насчитывающей более 800 историко-медицинских артефактов, и даже каменные рельефы XII века из храма Айраватешвара в Тамилнаду, изображающие практики родовспоможения. «История медицины предлагает карту того, как цивилизации понимали здоровье», — отмечает доктор Сакетх Рам Тригулла, научный сотрудник NIIMH.
Параллельно развивается национальная ИИ-инициатива BharatGen, создающая языковые модели для 15 индийских языков с планами расширения до 22. Для обработки рукописей без передачи данных в облако разрабатываются edge-устройства стоимостью до 50 000 рупий, позволяющие обрабатывать тексты локально. Также создаются специализированные модели: Ayur Param для аюрведических текстов, Agri Param для сельскохозяйственных трактатов и Legal Param для юридических документов.
Однако, несмотря на прогресс в распознавании символов, главный вызов — интерпретация смысла — остаётся нерешённым. Профессор Арджун Гхош из IIT Delhi подчёркивает: «Мир рукописей несоизмеримо разнообразнее мира печатных текстов». Один и тот же язык может быть записан разными письменностями, а для ряда индийских шрифтов доступны лишь сотни обучающих примеров вместо необходимых сотен тысяч. Понимание исторического и культурного контекста по-прежнему требует участия учёных-гуманитариев.
Проект имеет значение далеко за пределами Индии: он демонстрирует новую модель применения ИИ в гуманитарных науках, где технология не заменяет учёных, а радикально ускоряет их работу. Если раньше расшифровка 200-страничного манускрипта занимала месяцы, то ИИ-ассистенты сокращают этот срок в разы. Успех миссии может вдохновить аналогичные проекты в других странах с богатым рукописным наследием — от Египта до Китая, — открывая доступ к знаниям, скрытым в миллионах неразобранных документов по всему миру.





